Con l’esplosione dei big data, le organizzazioni stanno cercando di database NoSQL distribuiti per gestire l’enorme volume di dati che devono archiviare ed elaborare. Cassandra, Couchbase e MongoDB sono alcuni dei database NoSQL più popolari in uso oggi, ciascuno con i propri punti di forza e di debolezza.
Scegliere il database giusto per la tua organizzazione può essere un compito arduo, poiché ogni database ha caratteristiche e capacità uniche. In questo post approfondiremo questi tre database ed esploreremo le loro prestazioni, scalabilità e facilità d’uso.
È essenziale valutare attentamente fattori quali scalabilità, facilità d’uso, modellazione dei dati, capacità di interrogazione e supporto della comunità prima di prendere una decisione. Considerare le dimensioni e la complessità del set di dati, nonché il carico di lavoro previsto, ti aiuterà a scegliere il database distribuito giusto in linea con gli obiettivi del tuo progetto.
Introduzione ai database NoSQL distribuiti
I database NoSQL distribuiti hanno rivoluzionato il modo in cui le organizzazioni gestiscono grandi quantità di dati. Con la crescita esplosiva delle applicazioni digitali e la necessità di soluzioni di archiviazione scalabili e ad alte prestazioni, i database relazionali tradizionali spesso non riescono a soddisfare queste esigenze moderne.

A differenza dei database relazionali che si basano su uno schema strutturato, i database NoSQL offrono un modello di dati flessibile, consentendo l’archiviazione e il recupero di dati non strutturati e semistrutturati. Ciò che distingue i database NoSQL distribuiti è la loro capacità di distribuire i dati su più server o nodi, garantendo elevata disponibilità, tolleranza agli errori e scalabilità.
Panoramica dei database NoSQL ditribuiti: Cassandra, Couchbase e MongoDB
Cassandra, sviluppato da Facebook, è un database altamente scalabile e con tolleranza agli errori progettato per gestire grandi quantità di dati su più server di prodotti. È noto per la sua capacità di gestire un throughput di scrittura elevato e fornire scalabilità lineare.
L’architettura decentralizzata e il supporto per la replica su più data center lo rendono una scelta affidabile per le implementazioni globali.
Couchbase, d’altro canto, è un database NoSQL open source che combina la scalabilità degli archivi di valori-chiave con la flessibilità dei database di documenti. Offre un’architettura distribuita con funzionalità di caching e replica integrate, che consentono prestazioni elevate e tolleranza agli errori.
Couchbase fornisce inoltre supporto per query e indicizzazioni complesse, rendendolo adatto per applicazioni che richiedono analisi ed elaborazione dei dati in tempo reale.
MongoDB, noto per il suo modello di dati orientato ai documenti, è una scelta popolare tra gli sviluppatori grazie alla sua flessibilità e facilità d’uso. Memorizza i dati in un formato simile a JSON chiamato BSON, consentendo la progettazione dinamica di schemi e una facile integrazione con i moderni linguaggi di programmazione.
La scalabilità si ottiene tramite lo sharding, che consente il ridimensionamento orizzontale su più server. Fornisce inoltre avanzate funzionalità di query, incluso il supporto per query geospaziali e ricerca full-text.
Sebbene tutti e tre i database offrano soluzioni distribuite e scalabili per la gestione di grandi volumi di dati, le architetture e le funzionalità sottostanti differiscono. Comprendere i punti di forza e di debolezza di ciascun database è fondamentale per prendere una decisione informata per il tuo caso d’uso specifico.
Metriche prestazionali da considerare
Dobbiamo considerare le varie metriche prestazionali per prendere una decisione informata per il tuo caso d’uso specifico. Ecco alcuni fattori chiave da esaminare:
1. Latenza: si riferisce al tempo impiegato da un database per rispondere a una query. Una latenza inferiore significa tempi di risposta più rapidi, il che è vitale per le applicazioni che richiedono elaborazione dei dati in tempo reale o transazioni ad alta velocità. L’analisi della latenza delle operazioni di lettura e scrittura su diversi sistemi di database può fornire informazioni dettagliate sulle loro capacità prestazionali.
2. Throughput: misura la quantità di dati che un database può elaborare in un determinato intervallo di tempo. Viene generalmente misurato in termini di query o operazioni al secondo (QPS/OPS). Una velocità effettiva più elevata significa che il database può gestire un volume maggiore di richieste simultanee, garantendo un recupero e un’archiviazione efficienti dei dati.
3. Scalabilità: i database distribuiti sono progettati per scalare orizzontalmente, consentendo loro di gestire carichi di lavoro di dati in crescita. La valutazione della scalabilità di ciascun database implica l’analisi delle sue prestazioni all’aumentare delle dimensioni del set di dati e del carico di lavoro. Presta attenzione alla capacità del database di gestire il bilanciamento del carico e il partizionamento dei dati in modo efficace per garantire operazioni fluide man mano che la tua applicazione cresce.
4. Tolleranza ai guasti: i sistemi distribuiti sono soggetti a guasti ed è fondamentale valutare il modo in cui ciascun database gestisce tali scenari. Esamina funzionalità come la replica automatica dei dati, il rilevamento degli errori e i meccanismi di ripristino per garantire la durabilità e l’elevata disponibilità dei dati.
5. Coerenza dei dati: i database offrono diversi modelli di coerenza, che vanno dalla coerenza forte (garantendo la coerenza immediata dei dati tra le repliche) alla coerenza finale (consentendo incoerenze temporanee che vengono risolte nel tempo). Considera i requisiti della tua applicazione e il livello di coerenza dei dati fornito da ciascun database.
6. Funzionalità di indicizzazione e interrogazione: meccanismi efficienti di indicizzazione e interrogazione sono essenziali per un rapido recupero dei dati. Valuta le opzioni di indicizzazione disponibili in ciascun database e le prestazioni di diversi tipi di query (ad esempio, query su intervalli, ricerca full-text o query geospaziali) richieste dalla tua applicazione.
7. Facilità operativa: considerare la facilità di configurazione, amministrazione e manutenzione di ciascun database. Cerca funzionalità come lo sharding automatico, la gestione dei cluster, i meccanismi di backup e ripristino e gli strumenti di monitoraggio che semplificano le operazioni e riducono i costi generali.
Stabilire una metodologia di benchmarking completa
Per cominciare, è fondamentale identificare le metriche prestazionali specifiche che verranno valutate. Selezionando le metriche pertinenti, possiamo ottenere informazioni preziose sui punti di forza e di debolezza di ciascun database in diversi scenari.
Successivamente, è necessario progettare scenari di test realistici che simulino casi d’uso reali. Ciò comporta la creazione di modelli di dati appropriati, la generazione di carichi di lavoro significativi e la configurazione dei database con specifiche hardware simili. Imitando scenari applicativi reali, possiamo ottenere risultati prestazionali affidabili che riflettono il comportamento dei database in condizioni pratiche.
Per garantire equità e accuratezza, è importante eseguire più esecuzioni di ciascun benchmark per tenere conto di eventuali variazioni nei risultati. Ciò aiuta a mitigare eventuali valori anomali o anomalie che potrebbero verificarsi a causa di fattori esterni come la latenza della rete o il carico del sistema.
Confronto delle prestazioni: Operazioni di lettura
Cassandra, nota per la sua elevata scalabilità e tolleranza agli errori, eccelle nei carichi di lavoro ad alta intensità di lettura. La sua architettura distribuita consente una scalabilità lineare, il che significa che man mano che vengono aggiunti più nodi al cluster, le prestazioni di lettura migliorano.
Il modello dati, basato su un archivio chiave-valore con ampio supporto di colonne, consente operazioni di lettura efficienti anche con set di dati di grandi dimensioni. La capacità di replicare i dati su più nodi garantisce elevata disponibilità e bassa latenza per le richieste di lettura.
Couchbase, d’altra parte, è progettato per applicazioni interattive in tempo reale. La sua architettura basata sulla memoria sfrutta la potenza della RAM per fornire operazioni di lettura ultraveloci. Memorizzando in memoria i dati a cui si accede di frequente, Couchbase riduce al minimo l’I/O del disco, con conseguente riduzione significativa della latenza per le richieste di lettura.
Inoltre, il meccanismo di caching integrato di Couchbase consente un rapido recupero dei dati, rendendolo una scelta eccellente per le applicazioni che richiedono risposte a bassa latenza.
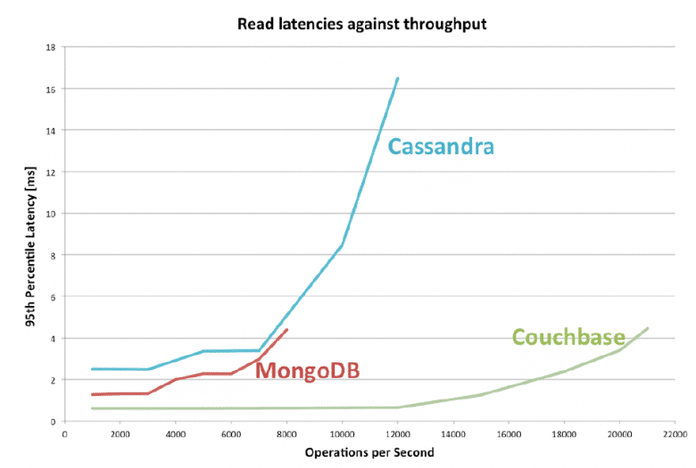
MongoDB offre eccellenti prestazioni di lettura grazie alle sue capacità di indicizzazione flessibili. Il motore di ottimizzazione delle query, alimentato dal motore di archiviazione WiredTiger, consente il recupero efficiente dei documenti in base a vari criteri. Sfruttando gli indici, MongoDB può individuare e recuperare rapidamente i dati richiesti, con conseguente operazioni di lettura più veloci. Inoltre, la capacità di scalare orizzontalmente consente un aumento del throughput di lettura man mano che il carico di lavoro cresce.

Quando si confrontano le prestazioni di questi database per le operazioni di lettura, è essenziale considerare i requisiti specifici della propria applicazione. Fattori quali modello di dati, scalabilità, meccanismi di memorizzazione nella cache e capacità di indicizzazione dovrebbero essere presi in considerazione per determinare la soluzione migliore per il proprio caso d’uso.
Confronto delle prestazioni: l’efficienza delle operazioni di scrittura
Cassandra, eccelle nei carichi di lavoro ad alta intensità di scrittura. Il suo modello di replica peer-to-peer e l’archiviazione dei dati ottimizzata consentono scritture ad alta velocità, rendendolo una scelta adatta per le applicazioni che richiedono operazioni di scrittura veloci e coerenti.
Inoltre, i livelli di coerenza regolabili offrono flessibilità nel compromesso tra coerenza e prestazioni migliori, adattandosi a diversi casi d’uso.
D’altra parte, Couchbase, con la sua architettura memory-first e meccanismi di caching avanzati, mostra anche prestazioni di scrittura impressionanti. Mantenendo in memoria i dati a cui si accede di frequente, Couchbase riduce al minimo le operazioni di I/O del disco, con conseguente bassa latenza e throughput elevato per le operazioni di scrittura.
Il supporto integrato per la durabilità dei dati garantisce che le scritture vengano mantenute in modo affidabile, anche in caso di errori.
MongoDB, grazie al suo schema flessibile e alle funzionalità di scalabilità orizzontale, è in grado di gestire grandi volumi di scritture in modo efficiente. Le opzioni relative ai problemi di scrittura consentono agli sviluppatori di ottimizzare i requisiti di durabilità, raggiungendo un equilibrio tra prestazioni e coerenza dei dati.
Tuttavia, vale la pena notare che le prestazioni di questi database possono variare a seconda del carico di lavoro e della configurazione specifici. Fattori come l’infrastruttura hardware, la latenza di rete, il modello di dati, le strategie di indicizzazione e i meccanismi di controllo della concorrenza possono influenzare in modo significativo i rispettivi profili prestazionali.
Scalabilità e disponibilità elevata
Cassandra, nota per la sua architettura robusta, è progettata per gestire enormi quantità di dati su più nodi. La sua natura distribuita gli consente di scalare orizzontalmente aggiungendo più nodi al cluster, garantendo che il database possa gestire carichi di lavoro crescenti man mano che l’applicazione cresce.
Couchbase, d’altro canto, offre un’architettura master-slave che consente il ridimensionamento orizzontale attraverso l’aggiunta di più nodi. Utilizza un algoritmo di hashing coerente per distribuire i dati nel cluster, garantendo una distribuzione uniforme del carico.
Grazie alle funzionalità di replica integrate, garantisce un’elevata disponibilità replicando automaticamente i dati su più nodi. In caso di guasto di un nodo, il sistema può reindirizzare senza problemi le richieste ad altri nodi disponibili, riducendo al minimo i tempi di inattività e garantendo un funzionamento continuo.
MongoDB, supporta anche il ridimensionamento orizzontale tramite lo sharding. Dividendo i dati in blocchi più piccoli e distribuendoli su più frammenti, può gestire set di dati di grandi dimensioni e carichi di traffico elevati.
In termini di elevata disponibilità, MongoDB utilizza set di repliche, in cui ogni set di repliche è costituito da un nodo primario e più nodi secondari. Se il nodo primario fallisce, uno dei nodi secondari viene eletto come nuovo primario, garantendo un servizio ininterrotto.
Quando si considerano scalabilità e disponibilità elevata, è importante valutare i requisiti specifici della propria applicazione. L’architettura decentralizzata e il design con tolleranza agli errori di Cassandra lo rendono una scelta eccellente per le applicazioni che richiedono scalabilità lineare e disponibilità elevata.
Couchbase offre un approccio equilibrato con la sua architettura master-slave e la replica automatica, garantendo scalabilità e disponibilità. Le funzionalità di partizionamento orizzontale e i set di repliche di MongoDB lo rendono una scelta adatta per le applicazioni che richiedono scalabilità e failover senza interruzioni.
Modello di dati e le capacità di query
Cassandra utilizza un modello di dati a famiglia di colonne. Puoi archiviare grandi quantità di dati strutturati, semistrutturati e non strutturati e scalarli facilmente in orizzontale per gestire carichi di lavoro elevati di scrittura e lettura. Le sue capacità di query sono focalizzate su operazioni di lettura e scrittura ad alta velocità e a bassa latenza, rendendolo una scelta popolare per le applicazioni in tempo reale.
Couchbase, d’altra parte, utilizza un modello di dati orientato ai documenti. Ciò significa che i dati vengono archiviati in documenti simili a JSON, fornendo uno schema flessibile e dinamico.
Con le ricche funzionalità di query di Couchbase, incluso il supporto per N1QL (JSON+SQL), puoi eseguire query e aggregazioni complesse sui tuoi dati. Offre inoltre funzionalità di ricerca full-text integrate, che lo rendono una scelta adatta per applicazioni che richiedono query e indicizzazione avanzate.
MongoDB, memorizza anche i dati in documenti simili a JSON. Il modello di documento consente una rappresentazione semplice ed efficiente di strutture dati complesse, rendendolo altamente adattabile alle esigenze applicative in evoluzione.
Con il suo potente linguaggio di query e le ricche opzioni di indicizzazione, MongoDB offre un’ampia gamma di funzionalità di query, incluso il supporto per query geospaziali e ricerca di testo. Inoltre, lo schema flessibile consente un’evoluzione dello schema e una migrazione dei dati senza soluzione di continuità.
Coerenza e durabilità
La coerenza si riferisce all’uniformità dei dati tra tutte le repliche o i nodi nel database distribuito. In un ambiente distribuito, raggiungere una forte coerenza può essere difficile a causa dei compromessi intrinseci tra coerenza, disponibilità e tolleranza alla partizione (noto come teorema CAP).
Cassandra, ad esempio, segue il modello di coerenza finale, in cui gli aggiornamenti vengono propagati in modo asincrono, consentendo un’elevata disponibilità ma sacrificando un certo livello di coerenza.
D’altra parte, Couchbase offre sia coerenza finale che opzioni fortemente coerenti, consentendo agli sviluppatori di scegliere il livello di coerenza richiesto per le loro applicazioni.
MongoDB segue un approccio simile con coerenza finale come impostazione predefinita, ma fornisce anche opzioni per una coerenza rigorosa quando necessario. Anche MongoDB offre durabilità attraverso la replica in cui i dati vengono replicati su più nodi, garantendo che anche in caso di errori, i dati rimangano intatti e accessibili.
La durabilità, invece, si riferisce alla capacità di un database distribuito di garantire che, una volta scritti, i dati siano persistenti e possano essere recuperati anche in caso di guasti. Tutti e tre i database citati dispongono di meccanismi per garantire la durabilità, come la replica e la registrazione write-ahead log.
Casi d’uso e considerazioni: Valutarli in base alle tue esigenze specifiche
Una considerazione importante è la scalabilità. Se la tua applicazione richiede elevata scalabilità e tolleranza agli errori, Cassandra potrebbe essere la scelta ideale. La sua architettura distribuita consente una scalabilità perfetta su più nodi, rendendolo particolarmente adatto per applicazioni che richiedono la gestione di grandi quantità di dati e operazioni di lettura e scrittura elevatemettere.
D’altra parte, se il tuo caso d’uso richiede una combinazione di prestazioni elevate, flessibilità e facilità d’uso, Couchbase potrebbe essere un forte concorrente. Con la sua architettura basata sulla memoria e il supporto per i documenti JSON, Couchbase fornisce accesso ai dati a bassa latenza e consente una facile integrazione con i moderni framework applicativi.
Nel frattempo, MongoDB offre un modello dati flessibile e senza schema, rendendolo una scelta eccellente per le applicazioni che richiedono frequenti modifiche allo schema o strutture dati in evoluzione. Le sue potenti capacità di query e la scalabilità orizzontale lo rendono adatto a un’ampia gamma di casi d’uso, inclusi sistemi di gestione dei contenuti, analisi in tempo reale e applicazioni mobili.
La sicurezza è un altro aspetto importante da considerare
Tutti e tre i database offrono varie funzionalità di sicurezza, come autenticazione, autorizzazione e crittografia, ma il livello di controllo e la facilità di implementazione possono variare. Valutare i tuoi requisiti di sicurezza specifici e comprendere le offerte di sicurezza di ciascun database ti aiuterà a prendere una decisione informata.
Una comunità fiorente può fornire risorse preziose, forum per la risoluzione dei problemi e aggiornamenti regolari al database. Una documentazione solida e un ricco ecosistema di strumenti, librerie e integrazioni possono avere un impatto significativo sulla produttività degli sviluppatori e sulla facilità di adozione.
Valutando attentamente il tuo caso d’uso, considerando scalabilità, prestazioni, flessibilità, sicurezza e supporto dell’ecosistema, puoi prendere una decisione informata in linea con i tuoi obiettivi e traguardi aziendali.
Scegliere il database NoSQL distribuito più adatto alle proprie esigenze
In primo luogo, se la scalabilità e l’elevata disponibilità sono le vostre massime priorità, Cassandra emerge come un forte concorrente. La sua architettura decentralizzata, il supporto per la scalabilità lineare e il design con tolleranza agli errori lo rendono la scelta ideale per le applicazioni che richiedono tempi di attività continui e la capacità di gestire enormi quantità di dati.
Se il tuo obiettivo invcece è la facilità d’uso e l’integrazione perfetta, Couchbase offre un’esperienza user-friendly con il suo approccio orientato ai documenti. Le funzionalità di memorizzazione nella cache integrate, la modellazione flessibile dei dati e le robuste funzionalità di query lo rendono un’opzione adatta per le applicazioni che richiedono elaborazione dei dati in tempo reale e tempi di risposta rapidi.
Infine, se il tuo progetto ruota attorno alla flessibilità e alla flessibilità dei dati, MongoDB offre una piattaforma potente e ricca di funzionalità. Il suo modello orientato ai documenti consente modifiche dinamiche dello schema, rendendolo adatto ad ambienti di sviluppo agili. Inoltre, il suo robusto linguaggio di query e le funzionalità di indicizzazione forniscono un efficiente recupero e analisi dei dati.
